
When you’re creating an account on a new app, you enter a username. But then you get this message “This username is already taken.” … and now you’ve got to think of 6 other creative names to give yourself.
Unfortunately, you’re not the only user out there in the world … we’re dealing with billions of people and their usernames. Checking whether a username exists cannot depend on simple database queries, if it did, you'll encounter problems like performance issues, high latency [time delays between sending a request for data and receiving it] & unnecessary loads on the system. We all like our systems working fast, don't we?

Wait, how in the world did it take the system less than a few milliseconds to find an existing username? Well, the efficiency you see - links to something called a hashmap. Think of hashmaps as really quick dictionaries - you feed the word (key) and it gives you the meaning (value). In reality though, hashmaps are a type of data structure that are used for efficient data storage and retrieval. Also called hash tables, these structures store data as key-value pairs. A hash function takes the key (e.g. a username string) and computes an index for it, enabling fast access to the values. Now you’d think the bigger the input data, the more time it takes to process it … right? More fruits in a smoothie, longer the wait? Nope. In this case, the algorithm’s execution time remains constant … even if the input increases in size.
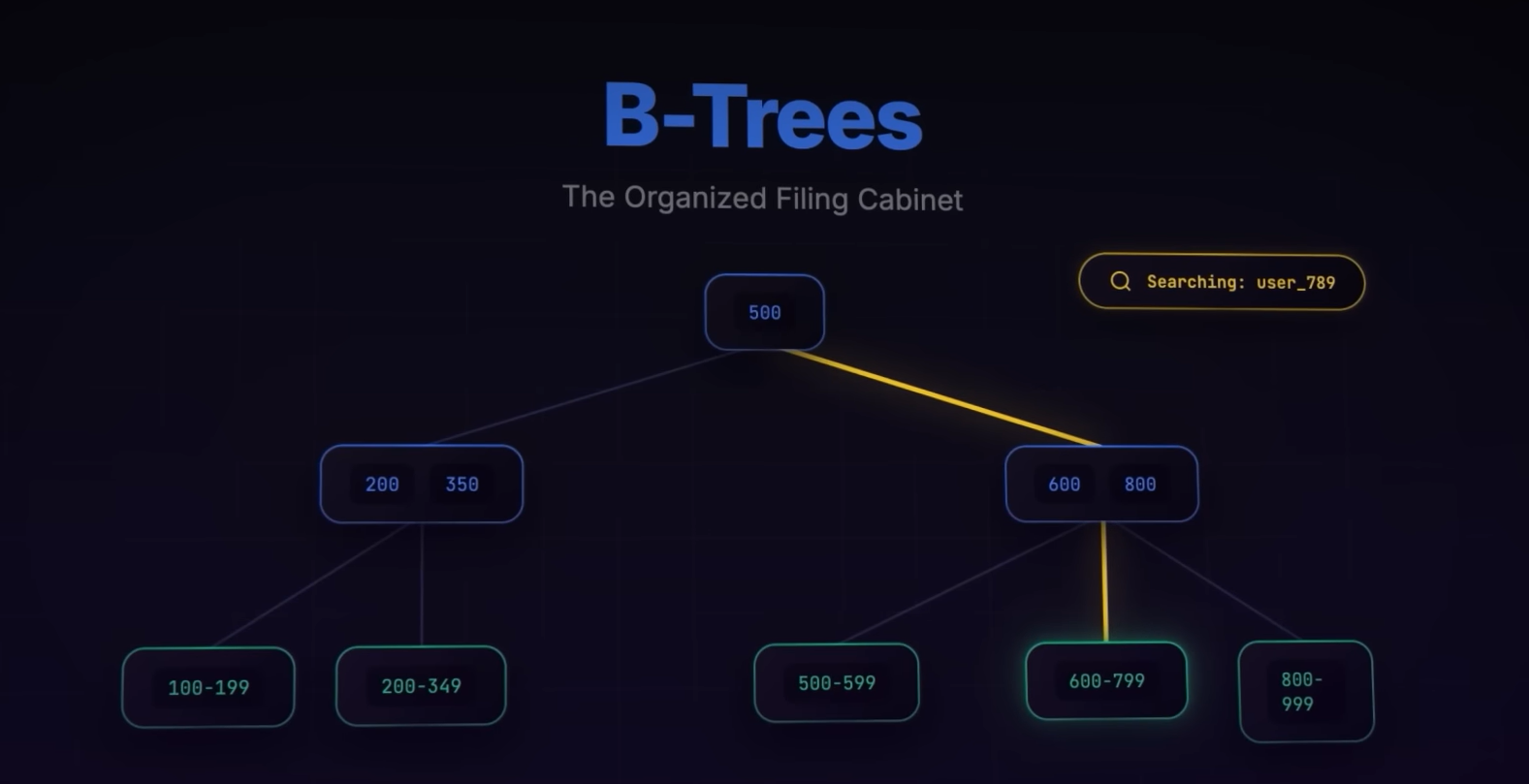
That’s all it takes…? Nah. Here’s where another structure comes into play. B+ Trees. This one might need half a page of breaking down … let’s try that in one paragraph. Think of these as libraries, the top shelves (internal nodes) only hold pointers to sections, and the actual books (data) are all stored neatly on the bottom shelves (leaf nodes). Every leaf is linked to the next one - which means you can quickly find the right section, then walk along the shelves to read data in a sorted order. Internal nodes store keys and pointers, but not actual records while leaf nodes contain all the data (records) and are linked sequentially for range scans.
Example - if you want all usernames ending with “789”, you jump to the right leaf & then follow the linked leaves.
Hold up … I need something memory efficient, lightning fast and doesn’t need to store the actual usernames. Say hello to bloom filters (no they’re not flowers, just another data structure). Here we go into the concept of probability - bloom filters are highly accurate and can tell you if something exists even if it might not know if it actually does. In technical terms - they’re probabilistic data structures that use bit arrays and hash functions to test if an element is in a set. For now, let’s imagine a bit array to be a row of switches all set to ‘0’. When you add an item, in this case a username, it’s fed through hash functions. Each hash function then will point to a position in the array, and those switches get flipped to ‘1’.
Does the item exist? Run it through the same hash functions:
If any switch is still 0 → the item is not present
If all switches are 1 → the item might be present (now go on and check the database)

A nested concept under bloom filters is - false positives vs. false negatives. A false positive is when the filter gives you false hope of the item existing when it doesn’t while false negative is when the filter tells you the item is not there and it really is non-existent. You might receive a false positive from it (when an element is not in the set, but it tells you it is) but NEVER a false negative (trust it when it says an element is non-existent in that particular set).
In the few milliseconds it takes for the system to tell you a username is taken, it goes through a multi-layer architecture that includes complex data structures. The next time your friends try to come up with a creative (but already taken) username, confuse them with these terms that, funnily enough large-scale companies like Amazon and Meta still use.



